文章: ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
作者: Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, Jian Sun
备注: Megvii
摘要
目前,神经网络体系结构设计主要以计算复杂度的 间接度量 为指导,即, FLOPs。然而,速度等直接指标也取决于其他因素,如内存访问成本和平台特性。因此,这项工作建议评估目标平台上的直接度量,而不仅仅是考虑 FLOPs。在一系列控制实验的基础上,提出了一些实用的网络设计准则。并依照这些准则, 提出了一种新的体系结构,称为ShuffleNet V2。综合消融实验证明,本文提出的模型在速度和精度上是最先进的。
Introduction
近年来的模型: VGG, GooLeNet, ResNet, DenseNet, ResNeXt, SE-Net
除了精度外,计算复杂度也是一个重要的考虑因素。现实世界中的任务通常旨在在有限的计算预算下获得最佳的精度,这是由目标平台(例如,硬件)和应用场景(例如,自动驾驶需要较低的延迟)给出的。这激发了一系列致力于轻量级架构设计和更好的速度精度权衡的工作,包括Xception[12]、MobileNet[13]、MobileNet V2[14]、ShuffleNet[15]和CondenseNet[16]等。在这些模型中,分组卷积(Group Conv)和深度卷积(Depth-wise Conv)是至关重要的。
为了度量计算复杂性,一个广泛使用的度量是浮点运算的数量,即 FLOPs。然而,FLOPs是一个间接指标。这是一个近似,但通常不等于本文真正关心的直接度量,比如速度或延迟。这种差异在以前的工作中已经注意到了[17,18,14,19]。例如,MobileNet v2 比 NASNET-A 快得多,但它们却有类似的 FLOPs。这种现象在图1(c)(d)中得到了进一步的体现,图1(c)(d)显示了具有类似故障的网络具有不同的速度。因此,仅用 FLOPs 作为计算复杂度的度量是不够的,可能会导致次优设计。

间接(FLOPs)和直接(speed)指标之间的差异可以归结为两个主要原因。
第一,几个对速度有很大影响的重要因素没有被FLOPs考虑在内。其中一个因素就是内存访问成本(MAC)。在某些操作(如组卷积)中,这样的开销占运行时的很大一部分。它可能成为计算能力强的设备(如gpu)的瓶颈。在网络体系结构设计中不应简单地忽略这一成本。另一个是并行度。在相同的失败情况下,并行度高的模型比并行度低的模型快得多。
第二, 同样的FLOPs操作根据平台的不同,可能会有不同的运行时间。例如,张量分解在早期的工作中被广泛使用[20,21,22]来加速矩阵的乘法。然而,最近的[19]研究发现,在GPU上[22]中的分解甚至更慢,尽管它减少了75%的FLOPs。本文调查了这个问题,发现这是因为最新的CUDNN[23]库是专门针对3×3 conv优化的,本文不能想当然的认为3×3 conv比1×1 conv慢9倍。
根据这些观察结果,本文建议在进行有效的网络架构设计时应考虑两个原则。首先,应该使用直接度量(例如,速度),而不是间接度量(例如,FLOPs)。其次,应该在目标平台上评估这些指标。
在这项工作中,本文遵循这两个原则,并提出了一个更有效的网络工作架构。在第2节中,本文首先分析了两种具有代表性的最先进网络的运行时性能[15,14]。在此基础上,本文提出了四种有效的网络设计准则,这些准则不仅仅是考虑 FLOPs。虽然这些指南是独立于平台的,但本文依然进行了一系列受控的实验,在两个不同的平台(GPU和ARM)上用专用的代码优化来验证它们,以确保本文的结论是最先进的。
在第三节中,本文根据准则设计了一个新的网络结构。因为它的灵感来自ShuffleNet[15],所以它被称为ShuffleNet V2。通过第4节的综合验证实验,在这两个平台上都比以前的网络更快、更准确。图1(a)(b)给出了比较情况的概览。例如,在计算复杂度预算为40M FLOPs的情况下,ShuffleNet v2的准确率分别比ShuffleNet v1和MobileNet v2高3.5%和3.7%。
Practical Guidelines for Efficient Network Design
本文的研究是在两个广泛采用的硬件与行业级优化的CNN库。本文注意到本文的CNN库比大多数开源库更有效。因此,本文保证本文的观察和结论是可靠的,对工业实践具有重要意义。
- GPU. A single NVIDIA GeForce GTX 1080Ti is used. The convolution li- brary is CUDNN 7.0 [23]. We also activate the benchmarking function of CUDNN to select the fastest algorithms for different convolutions respectively.
- ARM. A Qualcomm Snapdragon 810. We use a highly-optimized Neon-based implementation. A single thread is used for evaluation.
其他设置包括:打开全优化选项(例如张量融合,用于减少小操作的开销)。输入图像大小为224×224。每个网络被随机初始化并会评价100次, 使用平均运行时间作为最终结果.
为了开始本文的实验,本文分析了两种最先进的网络ShuffleNet v1[15]和MobileNet v2[14]的运行时性能。它们在图像分类任务中既高效又准确。它们都广泛应用于手机等低端设备。虽然本文只分析了这两个网络,但本文注意到它们代表了当前的趋势。它们的核心是分组卷积和深度卷积,这也是其他先进网络的关键组件,如ResNeXt[7]、Xception[12]、MobileNet[13]和CondenseNet[16].
根据不同的操作分解整个运行时间,结果如图2所示。本文注意到 FLOPs 只占有卷积部分。虽然这部分花费的时间最多,但是其他操作包括数据I/O、data shuffle 和 element-wise 操作(add张量、ReLU等)也需要相当长的时间。因此,只使用 FLOPs 对实际运行时进行估计不够准确。

基于这一观察,本文从几个不同的方面对运行时间(或速度)进行了详细的分析,并为高效的网络架构设计得出了几个实用的指导原则。
G1) 通道宽度相等,内存访问成本(MAC)最小
现代网络通常采用深度可分卷积[12,13,15,14],其中点态卷积(即 1×1 卷积)占了[15]复杂度的绝大部分。本文研究了1×1卷积的核形状, 发现其由两个参数指定: 输入通道 $c_1$ 和输出通道 $c_2$ 的数量。设 $h$ 和 $w$ 为 feature map 的空间大小,1×1 卷积的 FLOPs 为 $B = hwc_1c_2$
为了简单起见,本文假设计算设备中的缓存足够大,可以存储整个特征图谱和参数。因此,内存访问成本(MAC)或内存访问操作的数量是 $MAC = hw(c_1+c_2)+c_1c_2$。注意,这两项分别对应于输入/输出特性映射和卷积核权重的内存访问。
均值不等式,对于非负实数有 $a + b \geq 2\sqrt {ab}$, 并且仅当 $a=b$ 时才取得最小值, 由此本文得到:
推理过程如下:
因此,MAC有一个由FLOPs给出的下界。当输入通道和输出通道数目相等时,到达下界。
上面结论只是理论性的。实际上,许多设备上的缓存不够大。此外,现代计算库通常采用复杂的阻塞策略来充分利用缓存机制[24]。因此,实际MAC可能会偏离理论MAC。为了验证上述结论,本文进行了如下实验。通过重复叠加10个 building block 来构建基准网络。每个 block 包含两个卷积层。第一个包含c1输入通道和c2输出通道,and the second otherwise.(啥意思?)
表1通过改变 $c_1:c_2$ 的比例来测试运行速度,同时固定 FLOPs 不变。很明显,当 $c_1:c_2$ 接近 1:1 时,MAC变得更小,网络评估速度更快。

G2) 过多的 Group Conv 会增加 MAC
Group Conv 是现代网络结构的核心[7,15,25,26,27,28]。它通过将所有通道之间的密集卷积变的更稀疏(仅在通道组内)来降低计算复杂度(FLOPs)。一方面,它允许在给定 FLOPs 的情况下使用更多的通道,增加了网络容量(从而提高了准确性)。然而,另一方面, 通道数量的增加导致更多的 MAC。
形式上,1×1 Group Conv 的 MAC 和 FLOPs 之间的关系为
其中 $g$ 为组数,$B = hwc_1c_2 / g$ 为 FLOPs。可以看出,给定固定的输入形状 $c_1\times h\times w$ 和计算量 B, MAC 都随着 $g$ 的增大而增大。
为了验证 Group Conv 在实际应用中的影响,本文通过叠加 10个 pointwise group 卷积层,建立了一个基准网络。表2显示了在固定 FLOPs 不变时使用不同 group numbers 的运行速度. 很明显,使用较大的分组数量会显著降低运行速度。例如,在GPU上使用8组比使用1组(标准密集卷积)慢两倍多,在ARM上慢30%。这主要是由于MAC的增加。本文注意到,本文的实现经过了特别的优化,比一组一组地计算卷积要快得多。

因此,本文建议根据目标平台和具体任务谨慎的选择分组数量。使用较大的组号是不明智的,因为这可能会导致产生更多的通道,这样一来精度提高的好处很容易被快速增长的计算成本所抵消。
G3) 网络碎片化降低了并行度
在 GoogLeNet 系列[29,30,3,31]和自动生成的体系结构[9,11,10]中,每个网络块都广泛采用“多路径”结构。使用许多小的操作符(这里称为“片段操作符”),而不是一些大的操作符。例如,在NASNET-A[9]中,碎片操作符的数量(即一个 building block 中单个卷积或池化操作的数量)为13。相反,在像 ResNet 这样的常规结构中,这个数字是2或3。
虽然这种碎片化的结构已被证明有利于提高精度,但它可能会降低效率,因为它对GPU等具有强大并行计算能力的设备不友好。它还引入了额外的开销,比如 kernel launching 和信息同步(synchronization)
为了量化网络碎片化对效率的影响,本文评估了不同碎片化程度的网络块的结构。具体来说,每个构建块由1到4个1×1的卷积组成,这些卷积按顺序或并行排列。块结构如附录图1所示。每个网络块都会重复堆叠10次。

表3的结果显示,多段结构(即使是多段并行)在GPU上显著降低了速度,如4段结构比1段慢3倍。在ARM上,减速相对较小, 因为主要影响的是并行程度, 而 CPU 上主要进行串行计算.

G4) Element-wise 操作是不可忽略的
如图2所示,在轻量模型[15,14]中,element-wise 操作占用了相当多的时间,尤其是在GPU上。这里的元素操作符包括ReLU、Add Tensor、Add Bias等。它们的 FLOPs 较小,但 MAC 相对较高。特别地,本文还考虑了深度卷积(depthwise convolution)[12,13,14,15]作为一个 element-wise 运算符的情况,因为它也具有较高的MAC/FLOPs比。
为了验证本文的想法,本文在ResNet[4]中实验了 “bottleneck” 单元(1×1 conv + 3×3 conv + 1×1 conv, ReLU + Shortcut)。同时分别移除了 ReLU 和 Shortcut 操作。表4展示了不同变体的运行时间。可以看出, 在去除 ReLU 和 Shortcut 后,GPU 和 ARM 均获得了20%左右的加速。

结论和讨论
基于上述指导思想和实证研究,本文认为有效的网络架构应该遵循以下几点:
- 使用 “均衡” 的卷积(信道宽度相等);
- 在使用分组卷积(Group Conv)时, 需要注意带来的成本;
- 降低网络的破碎程度, 即不要过多的使用多路径的 block;
- 减少 element-wise 操作
这些特性的选择依赖于具体的平台(例如内存操作和代码优化),它们不仅仅依赖于 FLOPs。因此, 在实际的网络设计中, 应该同时考虑这些因素.
轻量级神经网络体系结构的最新进展[15,13,14,9,11,10,12]大多基于 FLOPs 度量,没有考虑上述特性。例如,ShuffleNet v1[15]严重依赖于组卷积(违反G2)和类似瓶颈的构建块(违反G1)。MobileNet v2[14]使用了一个违反G1的反向瓶颈结构。它使用深度卷积, 同时在一个很 “厚” 的特征图谱上使用 ReLU, 这违反了G4。自动生成的结构[9,11,10]高度碎片化,违反G3。
ShuffleNet V2: an Efficient Architecture
Review of ShuffleNet v1
根据 ShuffleNetV1,轻量级网络的主要挑战是,在给定的计算成本(FLOPs)下,只能负担得起有限数量的特征信道(feature channel)。为了在不显著增加 FLOPs 的情况下增加信道数量,ShuffleNetV1采用了两种技术: Point-wise Group Conv 和 bottleneck 结构。然后引入 “通道洗牌” 操作,使不同的通道组之间能够进行信息通信,从而提高准确性。构建块如图3(a)(b)所示。
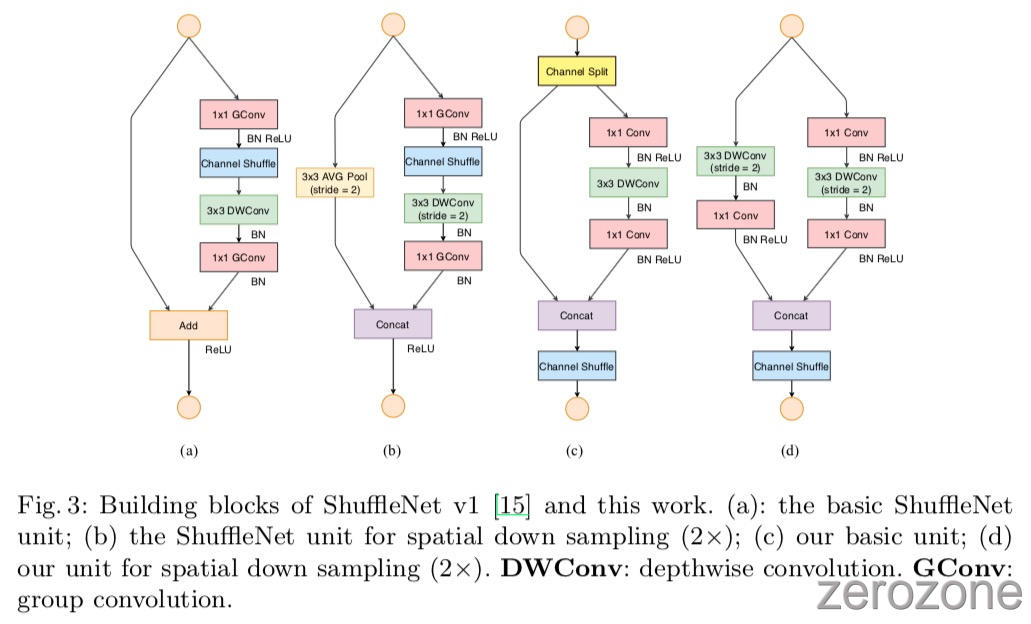
正如第2节所讨论的,Point-wise Group Conv 和 bottleneck 结构都增加了MAC(违反G1和G2)。这一成本是不可忽视的,特别是对轻量的模型。此外,使用太多分组违反了G3。Shortcut Connect 中的 element-wise add 操作也是不可取的(G4)。因此,为了达到高的模型容量和效率,关键问题是如何保持一个大的数量和同样宽的通道,既不进行密集卷积,也不使用过多的分组.
Channel Split and ShuffleNet V2
为了实现上述目的,本文引入了一个简单的操作符 Channel Split。如图3(c)所示。在每个单元的开始,将 $c$ 特征通道的输入分为两个分支,分别为 $c - c’$ 和 $c’$ 通道。根据 G3 原则,其中一个分支保持不变(相当于 Shortcut)。另一个分支由三个具有相同输入和输出通道的卷积组成,以满足G1。与 ShuffleNetV1 不同的是,这两个1×1卷积不再是 Group-wise 的, 其中部分原因是遵循G2,另一部分原因是 Channel Split 操作已经天然的生成了两个组。
经过 Shuffling 之后,下一个单元开始。注意,ShuffleNet v1中的 Add 操作不再存在。像ReLU和深度卷积这样的元素操作只会存在于一个分支中。此外,连续的三个元素操作(“Concat”, “通道洗牌” 和 “通道分割”)被合并为单个的 element-wise 操作。根据 G4 可知, 这种做法是有益的。
对于空间向下采样(spatial down sampling),本文对该单元进行了稍微修改,如图3(d)所示, 本文移除了 Channel Split 操作符。因此,输出通道的数量刚好增加了一倍(符合 down sampling 的特点)
本文提出的 building block (c)(d) 以及生成的网络称为 ShuffleNet V2。基于以上分析,本文得出结论,这种架构设计是高效的,因为它遵循所有的准则(G1~G4)。
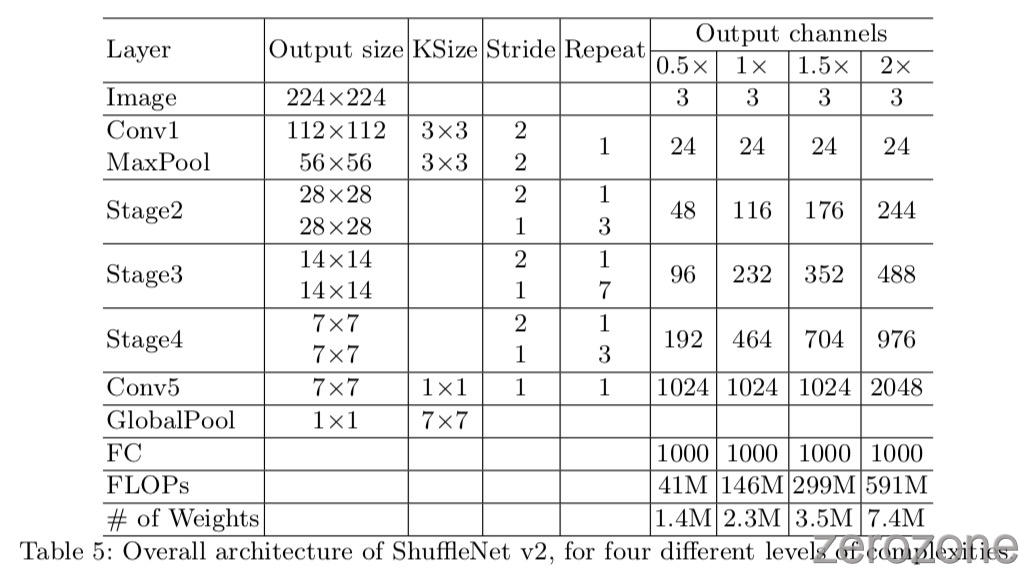
将这些 building-block 反复堆叠,进而构建整个网络。为了简单起见,本文设置 $c’ = c/2$。总体网络结构与ShuffleNet v1[15]相似,如表5所示。只有一个区别:在全局平均池之前添加一个传统的1×1卷积层来混合特性,而在ShuffleNet v1中没有。与[15]类似,将每个块中的信道数进行缩放,生成不同复杂度的网络,标记为0.5×、1×等。
Analysis of Network Accuracy
ShuffleNet v2不仅高效,而且准确。有两个主要原因:
- 首先,每个 building-block 的高效特性使得可以使用更多的特性通道和更大的网络容量
- 其次,在每个块中,有一半 feature channels (当 $c’ = c/2$ 时)直接穿过当前的 block 并加入下一个块。这可以看作是一种特征重用(feature reuse),这种思想来自于DenseNet[6]和CondenseNet [16]
在DenseNet[6]中,为了分析特征重用模式,绘制了层间权重的l1-norm,如图4(a)所示。很明显,相邻层之间的连接比其他层之间的连接更强。这意味着所有层之间的紧密连接可能会引入冗余。最近的CondenseNet[16]也支持这一观点.
在ShuffleNet V2中,很容易证明 $i-th$和 $(i+j)-th$ 构建块之间的“直接连接”通道的数量为 $r^jc$,其中 $r = (1 -c’)/c$。换句话说,特性重用量随着两个块之间的距离呈指数衰减。在距离较远的块之间,特性重用变得非常弱。图4(b)绘制了与图(a)类似的可视化,其中r = 0.5。注意(b)中的模式类似于(a)。
因此,ShuffleNet V2的结构通过设计实现了这种类型的特性重用模式。它具有与DenseNet[6]中类似的功能重用的优点,但如前所述,它的效率要高得多。 这在实验中得到验证,见表8。
Experiment
本文的消融实验是在ImageNet 2012分类数据集上进行的[32,33]。按照通常的做法[15,13,14],相比之下,所有网络都有四个级别的计算复杂度,即大约40、140、300和500+ MFLOPs。这种复杂性在移动场景中非常典型。其他超参数和协议与ShuffleNet v1[15]完全相同。
本文与以下网络架构进行了比较:
- ShuffleNet V1
- MobileNet V2
- Xception
- Densenet
表8总结了所有结果。本文从不同的角度分析这些结果。

准确性与 FLOPs
很明显,本文提出的的 ShuffleNet v2 模型在很大程度上优于其他所有网络,特别是在较小的计算预算下。此外,本文注意到 MobileNet v2 在 40 MFLOPs 级别上的表现很糟糕,其图像大小为224×224。这可能是由于 channels 太少造成的。相反,本文的模型没有这个缺点,因为本文的高效设计允许使用更多的通道。此外,虽然本文的模型和DenseNet[6]都重用了特性,但是本文的模型要有效得多,如第3节所讨论的。
表8还将本文的模型与其他最先进的网络进行了比较,包括 CondenseNet[16]、IGCV2[27]和IGCV3[28]。本文的模型在不同的复杂度级别上表现得更好。
Inference Speed vs. FLOPs/Accuracy
对于四种精度较好的架构ShuffleNet v2、MobileNet v2、ShuffleNet v1和Xception,本文将它们的实际速度(Actual Speed)与FLOPs进行比较,如图1(c)(d)所示。附录表1提供了关于不同分辨率的更多结果。

ShuffleNet v2显然比其他三个网络更快,尤其是在GPU上。例如,500MFLOPs ShuffleNet v2比MobileNet v2快58%,比ShuffleNet v1快63%,比Xception快25%。在ARM上,ShuffleNet v1、Xception和ShuffleNet v2的速度相当;然而,MobileNet v2要慢得多,尤其是在较小的失败。本文认为这是因为MobileNet v2有更高的MAC(参见第2节中的G1和G4),这在移动设备上非常重要。
与MobileNet v1[13]、IGCV2[27]和IGCV3[28]相比,本文有两个观察结果。首先,虽然MobileNet v1的精度不高,但是它在GPU上的速度比所有的同类产品都要快,包括ShuffleNet v2。本文认为这是因为它的结构满足大多数建议的准则(例如,对于G3, MobileNet v1的片段甚至比ShuffleNet v2更少)。其次,IGCV2和IGCV3速度较慢。这是由于使用了太多的卷积组(4或8在[27,28])。这两项意见都符合本文提出的准则。
最近,自动模型搜索[9,10,11,35,36,37]已经成为CNN结构设计的一个很有前途的趋势。表8的底部部分评估了一些自动生成的模型。本文发现它们的速度相对较慢。本文认为这主要是因为使用了太多的片段(参见G3)。尽管如此,这一研究方向仍然很有前景。例如,如果模型搜索算法与本文提出的准则相结合,并在目标平台上评估直接度量(速度),可能会得到更好的模型。
最后,图1(a)(b)总结了精度与速度(直接度量)之间的关系。本文得出结论,ShuffeNet v2在GPU和ARM上都是最好的。
与其他方法的兼容性
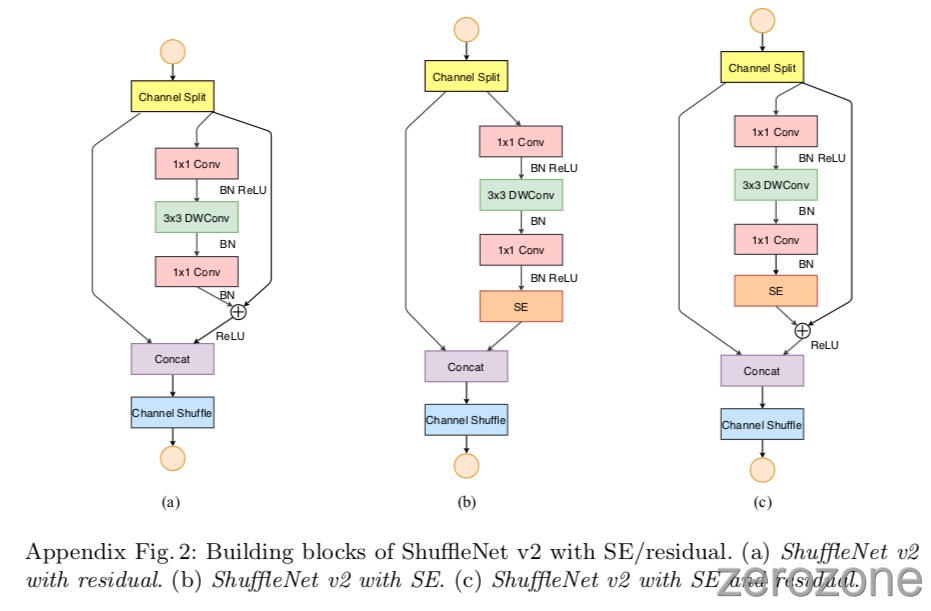
ShuffeNet v2可以与其他技术相结合,进一步提高性能。当使用 Squeeze-and-excitation(SE)模块[8]时,ShuffleNet v2的分类精度提高了0.5%,并且保证不会有大的速度损失。block 结构如下面的附录图2(b)所示。结果见表8(底部部分)。
对大型模型的泛化。
虽然作者的消融主要用于轻重量的情况下,ShuffleNet v2可以用于大型模型(e.g, FLOPs≥2G)。表6比较了50层ShuffleNet v2(详见附录)与ShuffleNet v1[15]和ResNet-50[4]的对应版本。ShuffleNet v2仍然在2.3GFLOPs上优于ShuffleNet v1,并且以40%的更少的FLOPs超过ResNet-50。
对于非常深的ShuffleNet v2(例如超过100层),为了使训练更快地收敛,作者通过添加一个残差路径(详见附录)来稍微修改基本的ShuffleNet v2单元。表6给出了一个包含164层的ShuffleNet v2模型,其中包含SE[8]组件(详见附录图2)。与以前的最先进的型号[8]相比,它在更少的 FLOPs 下获得了更高的精度。


目标检测
为了评估目标检测的泛化能力,作者还测试了COCO目标检测[38]任务。作者使用最先进的轻型检测: Light-Head RCNN[34] 作为作者的框架,并遵循相同的 training 和 testing 策略。只替换骨干网络。模型在ImageNet上进行预处理,然后对检测任务进行细化。除了minival set中的5000张图片外,作者使用COCO中的train+val set进行训练,并使用minival set进行测试。精度指标为COCO标准mmAP,即在box IoU阈值0.5到0.95之间的平均 mAPs。
将ShuffleNet v2与其他三个轻量级模型:Xception[12,34]、ShuffleNet v1[15]和MobileNet v2[14]在四个复杂级别上进行比较。表7中的结果显示ShuffleNet v2的性能最好。

将检测结果(表7)与分类结果(表8)进行比较,有趣的是,在分类时,准确率等级为ShuffleNet v2≥MobileNet v2 > ShuffeNet v1 > Xception,而在检测时,准确率等级变为ShuffleNet v2 > Xception≥ShuffleNet v1≥MobileNet v2。这说明,Xception在检测任务上表现良好。这可能是由于Xception构建块的感受野大于其他构建块(7 vs. 3)。受此启发,作者还通过在每个构建块的第一个点卷积之前引入额外的3×3深度卷积,来扩大ShuffleNet v2的接受域。这个变体表示为ShuffleNet v2*。在只增加少数额外的 FLOPs 情况,它可以进一步提高准确性。
作者还在GPU上测试运行时。为了公平比较,批处理大小被设置为4,以确保GPU的充分利用。由于数据复制(分辨率高达800×1200)等检测专用操作(如PSRoI池[34])的开销,不同模型之间的速度差距小于分类。尽管如此,ShuffleNet v2的性能仍然优于其他软件,例如,它比ShuffleNet v1快40%左右,比MobileNet v2快16%。
此外,变体ShuffleNet v2具有最好的精度,仍然比其他方法更快。这引发了一个实际的问题:*如何增加接受域的大小?这对于高分辨率图像[39]中的目标检测至关重要。 作者以后会研究这个话题。
Conclusion
作者提出了网络架构设计应考虑速度等直接指标,而不是FLOPs等间接指标。同时还提出了实用的指导方针和一个新的架构,ShuffleNet v2。综合实验验证了该模型的有效性。作者希望这项工作能够启发未来的网络架构设计工作,使其更具有平台意识和实用性.