文章: Squeeze-and-Excitation Networks
作者: Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu
备注: Momenta
摘要
卷积神经网络(CNN)的 central building block 是卷积运算符,其使得网络能够通过在每一层的局部感受野内融合空间和信道的信息来构建 informative features。大量先前的研究已经研究了这种关系的 spatial 部分(可以理解成特征图谱的尺寸),它们试图通过提高整个特征层次中空间编码的质量来增强CNN的表征能力。在这项工作中,作者将重点放在通道(channels)之间的关系上,并提出一个新的架构单元,作者称之为 “Squeeze-and-Excitation”(SE) block,它通过对通道之间的相互依赖性进行建模(explicitly modelling)来自适应地重新校准通道方面的特征响应。 作者的实验显示了这些块可以堆叠在一起形成 SENet 体系结构,该结构可以在不同数据集之间非常有效地进行泛化。进一步的, 作者还证明 SE 模块可以用最小的额外计算成本为现有的 SOTA CNN 带来显著的性能改进。 SENet 构成了作者的 ILSVRC 2017 分类任务提交的基础,该提交获得了第一名,并将 top-5 error 减少到 2.251%,超过了2016年的冠军模型,相对来说改善了~25%。
Introduction
目前已经证明,卷积神经网络(CNN)是处理各种视觉任务的有用模型。在网络中的每个卷积层,过滤器集合(卷积核)会沿输入通道来传送邻域空间内连通模式, 也就是将当前局部感受野内的 spatial 和 channel 的信息融合在一起。通过将一系列卷积层与非线性激活函数和下采样算子相互组合在一起,CNN能够产生捕获了 hierarchical patterns 同时获得全局理论感知野的 robust representations。最近的研究表明,通过将学习机制整合到网络中可以加强这些表示,这有助于捕获特征之间的 spatial correlations。其中 Inception 系列架构就是这种网络,可以将多尺度过程整合到网络模块中,以实现更高的性能。进一步的工作寻求更好地模拟空间依赖[7],[8]并将 spatial 注意力纳入网络结构[9]。
在本文中,作者研究了网络设计的不同方面, 即通道(channels)之间的关系。 作者引入了一个新的架构单元,作者将其称为 Squeeze-and-Excitation(SE)块,其目标是通过明确地模拟其卷积特征的通道之间的相互依赖性(interdependencies)来提高网络产生的表征质量。 为此,作者提出了一种机制,允许网络执行 特征重新校准(feature recalibration),通过该机制,它可以学习使用全局信息来选择性地强调信息特征并抑制不太有用的特征。
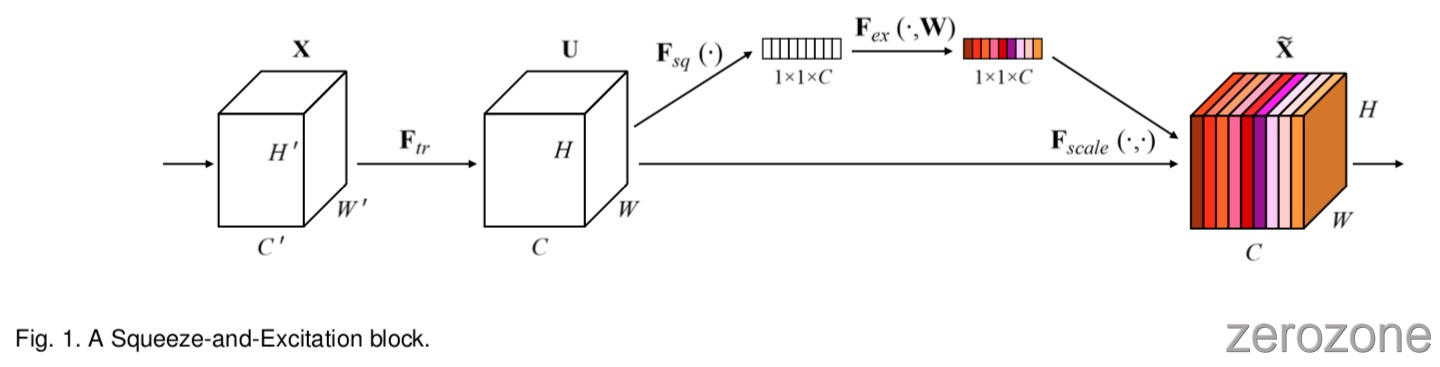
SE building block 的结构如图1所示. 对于任意的 transformation(e.g. a convolution) $F_{tr}: X \rightarrow U, X \in R^{H’\times W’ \times C’}, U \in R^{H\times W \times C}$, 作者都可以构建一个相应的 SE block 来进行 feature recalibration. 特征 $U$ 首先执行 Squeeze 操作,其通过在其空间维度(H×W)上聚合 feature maps 来产生信道描述符(channel descriptor)。 该描述符的功能是产生 channel-wise 特征响应的全局分布的 embedding,从而允许来自网络的全局感受野的信息被其所有层使用。 squeeze 之后是 excitation 操作,其采用简单的 self-gating 机制的形式,其将 embeddings 作为输入并产生每个通道上调制权重(modulation weights)的集合。 将这些权重应用于 feature map $U$ 之上以生成 SE block 的输出,其可以直接馈送到网络的后续层中。
可以通过简单地堆叠 SE block 的集合来构建 SE 网络(SENet)。此外,这些 SE 模块还可以用作网络体系结构中一定深度范围内 drop-in 的直接替代品(第6.4节)。虽然构建块的模板是通用的,但它在不同深度中执行的角色在整个网络中是不同的。 在早期的网络层中,它以类不可知(class-agnostic)的方式激发 informative features,加强共享的低级表征(low-level representations)。 在后面的层中,SE块变得越来越专业化(specialised),并以特定于类(class-specific)的方式对不同的输入产生响应. 因此,SE block 执行的特征重新校准(feature recalibration)带来的手艺可以在网络中逐渐累积。
新型 CNN 架构的设计和开发是一项艰巨的工程任务,通常需要选择许多新的超参数和网络层配置。 相比之下,SE 模块的结构很简单,可以通过用 SE 结构替换对应组件,来直接在现有的现有架构中使用 SE 模块,从而可以有效地提高性能。 SE块在计算上也是轻量级的,仅仅使模型的复杂性和计算负担略微增加。
作者设计了几个 SENets 并对 ImageNet 2012 数据集进行了广泛的评估[10]。 作者还提供ImageNet之外的结果,表明作者的方法的好处不仅限于特定的数据集或任务。 通过使用 SENets,作者在 ILSVRC 2017 分类竞赛中排名第一。 作者最好的模型集合在测试集上实现了 2.251% 的 top-5 error。 与上一年的获胜者(2.991%)相比,这相当于大约25%的相对改善
Related Work
VGGNets, BN, ResNets, NAS, Attention and gating mechanism
Squeeze-And-Excitation Blocks
Squeeze-and-Excitation block 是可以为任何给定 transformation $U = F_{tr}(X),X \in R^{H’×W’×C’},U\in R^{H×W×C}$ 构造的计算单元。为简单起见,在下面的符号中作者将 $F_{tr}$ 作为卷积运算符。 令 $V = [v_1,v_2,…,v_C]$ 表示学习到的滤波器核的集合,其中 $v_c$ 指的是第 $c$ 个滤波器的参数。然后作者可以将 $F_tr$ 的输出写为 $U = [u_1,u_2,…,u_C]$,其中.
这里的 $\ast$ 表示卷积,$v_c = [v^1_c, v^2_c, …, v^{C’}_c], X = [x^1, x^2, …, x^{C’}]$(为了简化符号,省略偏置项),$v_c^s$ 是一个 2D spatial 内核,表示作用于 $X$ 的相应通道的 $v_c$ 的单个通道。由于输出是通过所有通道的求和产生的,通道间的依赖关系会隐式的嵌入到 $v_c$ 中,并且与过滤器捕获的局部空间相关性纠缠在一起。因此,通过卷积建模的信道关系本质上是局部的。 由于作者的目标是确保网络能够提高其对信息功能的敏感度,以便最有效地利用后续转换,作者希望为其提供对全局信息的访问。 作者提出通过明确地建模通道相互依赖性来实现这一点,以便在它们被馈送到下一个 transformation之前,作者通过两个步骤(squeeze and excitation)来重新校准滤波器响应述。SE块的结构的图示于图1中。
Squeeze: Global Information Embedding
为了解决利用信道相关性的问题,作者首先考虑输出特征中每个信道的信号。 每个学习的过滤器都在局部感受野上进行操作,因此 transformation 的输出 $U$ 的每个单元不能利用该区域之外的上下文信息。
为了缓解这个问题,作者建议将全局空间信息压缩(squeeze)到一个通道描述符(channel descriptor)中。 这可以通过使用全局平均池化层来生成 channel-wise statistics 实现。 形式上,通过将 $U$ 按照其空间维度 $H×W$ 进行压缩进而生成统计量 $z\in R^C$(尺寸为 1, 深度为 $C$),使得 $z$ 的第 $c$ 个元素通过以下公式计算:
transformation $U$ 的输出可以被解释为其表征整个图像的局部描述符的集合。利用这些信息在以前的特征工程中很普遍。作者选择最简单的聚合技术,即 全局平均池化(GAP),实际上此处也可以采用更复杂的策略。
Excitation: Adaptive Recalibration
为了利用 squeeze 操作中聚合的信息,作者紧跟着执行第二个操作,旨在 完全捕获通道方面的依赖关系。 为了实现这一目标,该功能必须满足 两个标准:首先,它必须是灵活(flexible)的(它必须能够学习通道之间非线性的相互作用),其次,它必须学习非相互排斥(non-mutually-exclusive)的关系,因为作者会希望允许同时关注多个通道(而不是强制执行 one-hot 激活)。 为了满足这些标准,作者选择使用带有 sigmoid 激活的简单门控机制(gating mechanism):
上式中 $\delta$ 代表 ReLU 函数, $W_1 \in R^{\frac{C}{r}\times C}$, $W_2\in R^{C\times \frac{C}{r}}$. To limit model complexity and aid generalisation, we parameterise the gating mechanism by forming a bottleneck with two fully connected (FC) layers around the non-linearity, i.e. a dimensionality-reduction layer with parameters W1 and reduction ratio r (this parameter choice is discussed in Sec. 6.1), a ReLU and then a dimensionality-increasing layer with parameters W2. The final output of the block is obtained by rescaling the transformation output U with the activations:
上式中, $\tilde X = [\tilde x_1, \tilde x_2, …, \tilde x_C]$ 和 $F_{scale}(u_c, s_c)$ 是指标量 $s_c$ 和 feature map $u_c \in R^{H×W}$ 之间的 channel-wise multiplication.
excitation operator 将输入特定描述符 $z$ 映射到一组具有特定权重的通道上。 在这方面,SE 模块本质上引入了以输入为条件的动态因素,有助于提高特征可辨性。
Instantiations
SE block 可以通过在每个卷积之后的非线性激活层之后插入而集成到诸如VGGNet [11]的标准体系结构中。 此外,SE block 的灵活性意味着它可以直接应用于除了标准卷积的其他 transformations。 为了说明这一点,作者通过将 SE 块集成到更复杂架构的几个示例中来开发SENets,如下所述。
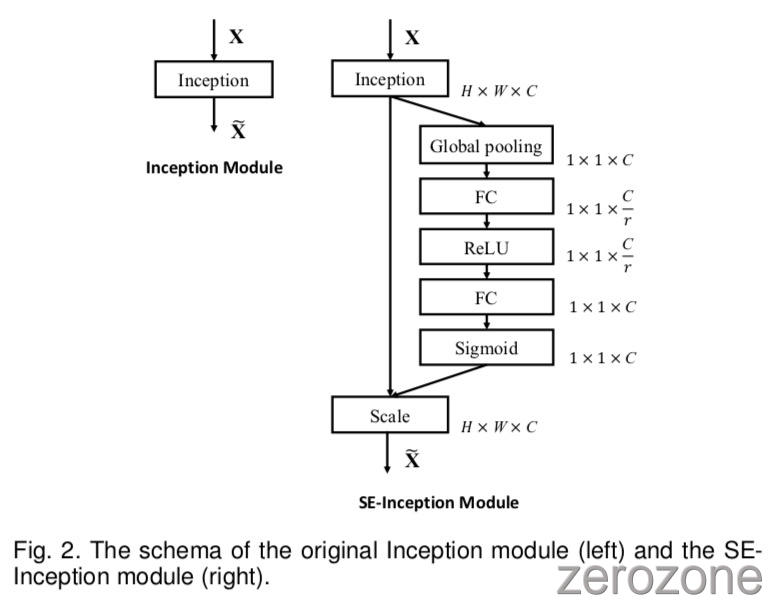
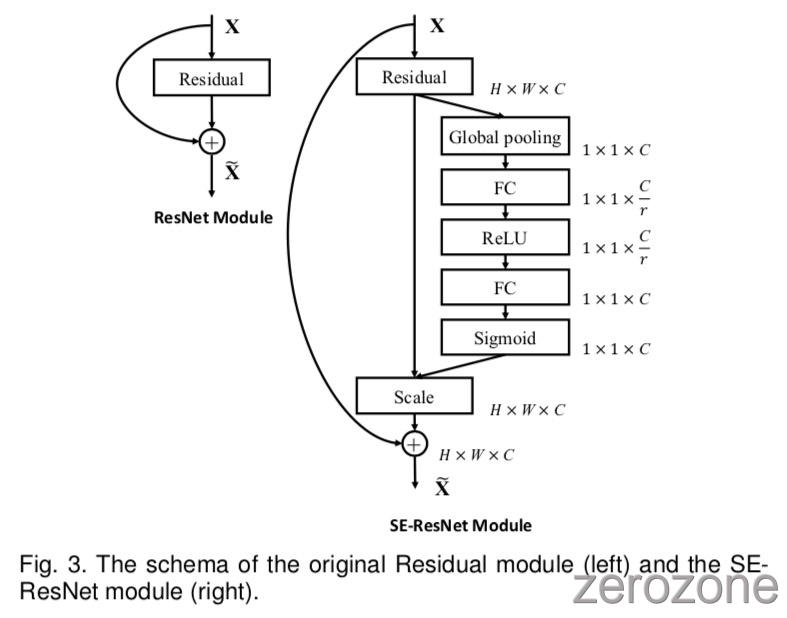
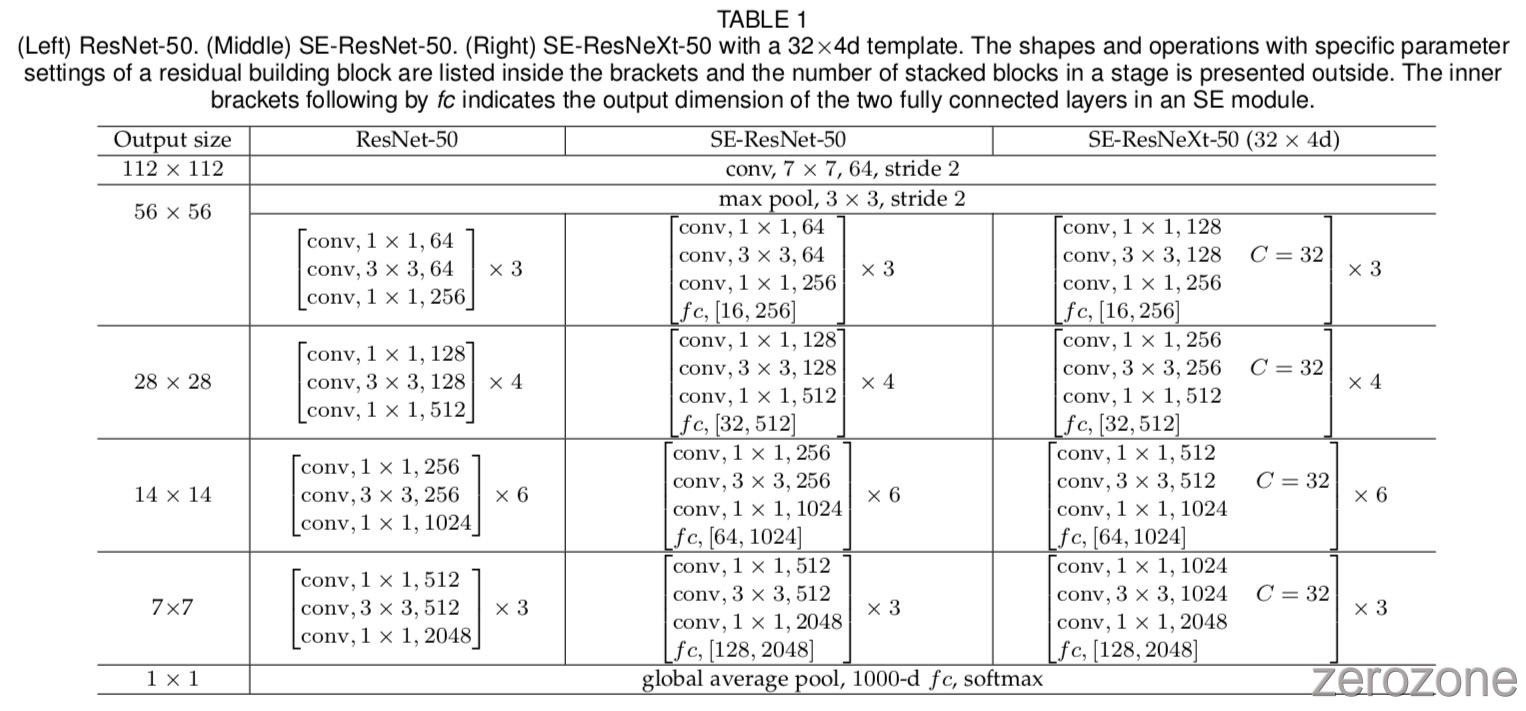
作者首先考虑为 Inception 网络构建 SE 块[5]。 在这里,作者简单地将 transformation $F_{tr}$ 作为一个完整的Inception模块(参见图2),并通过对架构中的每个这样的模块进行此更改,作者获得了 SE-Inception 网络。SE块也可以直接与 ResNet 一起使用(图3描绘了 SE-ResNet 模块的结构)。这里,SE块的 transformations $F{tr}$ 被认为是残差模块的非同一分支。 Squeeze 和 Excitation 都在与 identity 分支求和之前起作用。 将SE块与ResNeXt [19],Inception-ResNet [21],MobileNet [65]和ShuffleNet [66]集成的其他变体可以通过遵循类似的方案(第5.1节)来构建。 对于SENet架构的具体示例,表1中给出了 SE-ResNet-50 和 SE-ResNeXt-50 的详细描述。
SE 模块由于自身的灵活性,使得有几种可行的方式可以将它集成到这些体系结构中。 因此,为了评估用于将 SE block 整合到网络架构中的集成策略的敏感性,作者还提供相关的消融实验,探索添加 block 的不同设计。
Model And Computational Complexity
为了使所提出的SE模块设计具有实用性,它必须在改进的性能和增加的模型复杂性之间提供良好的折衷。除非另有说明,否则作者在所有实验中将 reduction ratio $r$(在3.2节中介绍)设定为16。为了说明与模块相关的计算负担,作者考虑将 ResNet-50 和 SE-ResNet-50 之间的比较作为示例。对于 224×224 像素的输入图像,ResNet-50在单个 forward pass 中需要〜3.86 GFLOPs。每个 SE 模块利用 squeeze 阶段的全局平均池化操作和 excitation 阶段中的两个小的 FC,然后进行计算量较低的通道缩放操作(channel-wise scaling)。总的来说,SE-ResNet-50需要~3.87 GFLOPs,相当于原始ResNet-50相对增加0.26%。加上这种轻微的额外计算负担之后,SE-ResNet-50的准确度超过了ResNet-50的准确度,实际上,接近了需要~7.58 GFLOPs的 ResNet-101 网络的准确性。如下面的表2所示

实际上,ResNet-50完成一次 forward 和 backward 传递需要 190ms,相比之下,SE-ResNet-50 需要 209 ms才能获得256张图像的训练小批量(两个计时都在具有8个NVIDIA Titan X GPU的服务器上执行)。 作者认为这是合理的运行时开销,随着全局池和小型内部产品操作在流行的GPU库中获得进一步优化,这可能会进一步减少。 由于其对嵌入式设备应用的重要性,作者进一步对每个型号的CPU推理时间进行基准测试:对于224×224像素输入图像,ResNet-50需要 164ms而 SE-ResNet-50 需要 167ms。 作者认为,SE block 产生的额外计算成本很小,因此它对模型性能的贡献是合理的。
接下来作者考虑 SE block 引入的附加参数。这些附加参数仅来自 gating mechanism 的两个 FC 层,因此只构成总网络容量的一小部分。 具体而言,拟议方法引入的附加参数总数由下式给出:
其中 $r$ 表示 reduction ratio,$S$ 表示 stages 的数量( stages 是指在共同空间维度的特征图上运行的块集合),$C_s$ 表示输出通道的维数,$N_s$ 表示对于 $s$ 阶段重复块的数量。SE-ResNet-50引入了大约250万个附加参数,超出了ResNet-50所需的~2500万个参数,相当于增加了~10%。 实际上,这些参数中的大多数来自网络的最后阶段,其中 excitation 操作需要在最大数量的信道上执行。 然而,作者发现 SE块的这个相对昂贵的最后阶段可以在很小的性能成本(ImageNet上<0.1%的前5个误差)中消除,从而将相对参数增加减少到~4%,这在实际中中可能是有用的, 因为参数的数量也是一个关键考虑因素
Experiments
Image Classification
为了评估SE块的影响,作者首先在ImageNet 2012数据集[10]上进行实验,其中包括来自1000个不同类别的128万个训练图像和50K验证图像。 作者在训练集上训练网络并报告验证集上的前1和前5错误。
每个原始网络架构及其相应的SE对应物都使用相同的优化方案进行训练。 作者遵循标准做法并使用随机裁剪[5]进行数据增加,尺寸为224×224像素(或者Inception-ResNet-v2 [21]和SE-Inception-ResNet-v2为299×299)并执行随机水平翻转。 通过平均RGB通道减法对每个输入图像进行归一化。 作者采用[67]中描述的数据平衡策略进行小批量采样。 所有模型都在作者的分布式学习系统ROCS上进行培训,该系统旨在处理大型网络的高效并行训练。 使用具有动量0.9和小批量大小1024的同步SGD执行优化。初始学习速率设置为0.6并且每30个时期减少10倍。 使用[68]中描述的权重初始化策略,所有模型都从头开始训练100个时期。
在评估模型时,作者应用中心裁剪,以便在每个图像的较短边首次调整为256之后从每个图像中裁剪224×224像素(对于Inception-ResNet-v2和SE-Inception-ResNet-v2,每个图像的299×299,其较短边首先调整为352)。
Network depth: 作者首先将SE-ResNet与不同深度的ResNet架构进行比较,然后在表2中报告结果。作者观察到SE块在不同深度上的性能不断提高,计算复杂度极小。值得注意的是,SE-ResNet-50实现了单一 crops 前5个验证误差6.62%,超过ResNet-50(7.48%)0.86%并接近更深层次的ResNet-101网络所达到的性能(6.52%top- 5错误)仅占总计算负担的一半(3.87 GFLOPs与7.58 GFLOPs)。这种模式在更深的地方重复出现,其中SE-ResNet-101(6.07%前5个错误)不仅匹配,而且优于更深的ResNet-152网络(6.34%前5个错误)0.27%。虽然应该注意SE块本身增加深度,但它们以极其计算效率的方式这样做,并且即使在扩展基础架构的深度实现递减收益的点处也产生良好的回报。此外,作者看到增益在一系列不同的网络深度上是一致的,这表明SE块引起的改进可能与通过简单地增加基础架构的深度所获得的改进互补。
Integration with modern architectures: 接下来作者研究了将SE模块与两个最先进的架构,Inception-ResNet-v2 [21]和ResNeXt(使用32×4d的设置)[19]集成的效果,两者都引入了额外的计算 构建块进入基础网络。 作者构建这些网络的SENet等价物,SE-Inception-ResNet-v2和SE-ResNeXt(表1中给出了SE-ResNeXt-50的配置)并在表2中报告结果。与之前的实验一样,作者观察到显着的 通过将SE块引入两种体系结构而引起的性能改进。 特别是,SE-ResNeXt-50的前5个误差为5.49%,优于其直接对手ResNeXt-50(5.90%前5个误差)以及更深的ResNeXt-101(5.57%前5个) 错误),一个几乎是参数总数和计算开销的两倍的模型。 作者注意到作者重新实现Inception-ResNet-v2与[21]中报告的结果之间的性能略有不同。 然而,作者观察到关于SE块的影响的类似趋势,发现SE-Inception-ResNet-v2(4.79%前5个错误)优于作者重新实现的Inception-ResNet-v2基线(5.21%前5个错误) 在[21]中报告的结果为0.42%(相对改善率为8.1%)。 基线架构ResNet-50,ResNet-152,ResNeXt-50和BN-Inception的训练曲线以及它们各自的SE对应物如图4所示。作者观察到SE块在整个优化过程中产生稳定的改进。 此外,这种趋势在被视为基线的最先进架构的每个系列中都是一致的。

作者还通过使用VGG-16 [11]和BN-Inception架构[6]进行实验来评估SE块在非残留网络上运行时的影响。 为了便于从头开始训练VGG-16,作者在每次卷积后添加批量标准化层。 与之前的型号一样,作者对VGG-16和SE-VGG-16使用相同的培训方案。 比较结果如表2所示。与残留基线架构报告的结果类似,作者观察到SE块改善了性能。
Mobile setting: 最后,作者考虑移动优化网络中的两种代表性架构,MobileNet [65]和ShuffleNet [66]。 对于这些实验,作者使用256的小批量和 $4×10^{-5}$ 的重量衰减。 作者使用具有动量(设置为0.9)的SGD和初始学习率为0.1的8个GPU训练模型,每次验证损失稳定时(而不是使用固定长度的时间表),该模型减少了10倍。 整个训练过程需要约400个时期(作者发现这种方法使作者能够重现[66]的基线性能)。 表3中报告的结果表明,SE块在计算成本的最小增加的情况下大大提高了准确度。

Additional datasets: 接下来,作者将研究SE块的优势是否可以推广到ImageNet之外的数据集。作者在CIFAR上使用几种流行的基线架构和技术(ResNet-110 [14],ResNet-164 [14],WideResNet-16-8 [69],Shake-Shake [70]和Cutout [71])进行实验 - 10和CIFAR-100数据集[73]。这些包括50k训练和10k测试32×32像素RGB图像的集合,分别标记为10和100类。将SE块集成到这些网络中的方法遵循第二节中描述的相同方法。 3.3。每个基线及其SENet对应物都采用标准数据增强策略进行训练[24],[74]。在训练期间,图像随机水平翻转并在每侧采用零填充,具有四个像素,然后进行随机32×32裁剪。还应用均值和标准偏差归一化。训练策略和其他超参数的设置(例如,小批量大小,初始学习率,时期数,重量衰减)与每个模型的作者建议的那些匹配。作者在表4中报告了CIFAR-10上每个基线及其SENet对应物的性能以及表5中CIFAR-100的性能。作者观察到在每次比较中SENets都优于基线架构,这表明SE块的好处不受限制到ImageNet数据集。


Scene Classification
接下来,作者对Places365-Challenge数据集[75]进行实验,以进行场景分类。 该数据集包含800个培训图像和365个类别的36,500个验证图像。 相对于分类,场景理解的任务提供了对模型的概括和处理抽象的能力的替代评估。 这是因为它通常要求模型处理更复杂的数据关联,并且对更高级别的外观变化具有鲁棒性。
作者选择使用ResNet-152作为评估SE模块有效性的强大基线,并仔细遵循[72]中描述的培训和评估协议。 在这些实验中,所有模型都是从头开始训练的。 作者在表6中报告结果,并与之前的工作进行比较。 作者观察到SE-ResNet-152(11.01%前5个错误)实现了比ResNet-152更低的验证错误(11.61%前5个错误),提供了SE块也可以改进场景分类的证据。 这个SENet超越了之前最先进的模型Places-365-CNN [72],该任务的前5个误差为11.48%。

Object Detection on COCO
作者使用COCO数据集[76]进一步评估SE块对物体检测任务的推广,其中包括80k训练图像和40k验证图像,遵循[13]中使用的分割。 作者使用更快的R-CNN [4]检测框架作为评估模型的基础,并遵循[13]中描述的基本实现。 作者的目标是评估使用SE-ResNet替换对象检测器中的主干架构(ResNet)的效果,以便可以将性能的任何变化归因于更好的表示。 表7报告了使用ResNet-50,ResNet-101及其SE对应物作为主干架构的对象检测器的验证集性能。 SE-ResNet-50在COCO的标准AP指标上优于ResNet-50 1.3%(相对5.2%的改进),在AP@IoU=0.5上优于1.6%。 SE模块还对更深层次的ResNet-101架构进行了改进,使AP指标的性能提高了0.7%(相对改进率为2.6%)。

总之,这组实验表明SE块带来的改进可以在十分广泛的架构,任务和数据集中生效。
ILSVRC 2017 Classification Competition
SENets成为作者提交ILSVRC竞赛的基础,作者获得了第一名。 作者的获奖作品包括一小部分SENets,采用标准的多尺度和多 crops 融合策略,在测试集上获得2.25%的前5个误差。作为本次提交的一部分,作者通过将SE块与修改后的ResNeXt [19](附录中提供了架构的详细信息)进行了整合,构建了一个额外的模型SENet-154。 作者使用标准裁剪尺寸(224×224和320×320)将此模型与表8中ImageNet验证集的先前工作进行比较。 作者观察到SENet-154使用224×224中心 crop 评估获得了18.68%的前1个误差和4.47%的前5个误差,这代表了最强的报告结果。

在挑战赛结束之后,ImageNet基准测试取得了很大进展。 为了进行比较,作者在表9中的已发表和未发表的文献中包含了作者目前所知的最强结果。最近报道了仅使用ImageNet数据的最佳性能[79]。 该方法使用强化学习在训练期间开发用于数据增强的新策略,以改善[31]提出的体系结构的性能。 [80]使用ResNeXt-101 32×48d架构报告了最佳整体性能。 这是通过在大约10亿个弱标签图像上预先训练他们的模型并在ImageNet上进行微调来实现的。 通过更复杂的数据增强[79]和广泛的预训练[80]所产生的改进可能是作者对网络架构的拟议更改的补充。

Ablation Study
在本节中,作者进行消融实验,以更好地理解SE模块设计中组件的相对重要性。 所有消融实验均在单台机器上的ImageNet数据集上执行(具有8个GPU)。 ResNet-50用作骨干架构。 数据增强策略遵循第二节中描述的方法。5.1。 为了让作者研究每个变体的性能上限,将学习率初始化为0.1,并且继续训练直到验证失去平稳(而不是持续固定数量的时期)。 然后将学习率降低10倍,然后重复该过程(总共三次)。
Reduction ratio
公式5中引入的 reduction ratio $r$ 是一个超参数,其允许作者改变网络中SE块的容量和计算成本。 为了研究由这个超参数介导的性能和计算成本之间的权衡,作者使用SE-ResNet-50对一系列不同的r值进行了实验。 表10中的比较表明,性能不会随着容量的增加而单调改善,这表明SE块具有足够的权重,能够过度拟合训练集的信道相互依赖性。 作者发现 $r = 16$ 的设置在准确性和复杂性之间取得了很好的平衡,因此,作者将这个值用于本工作中报告的所有实验。

Squeeze Operator
作者研究了使用全局平均池而不是全局最大池作为作者选择的 squeeze 算子的重要性(作者没有考虑更复杂的替代方案)。 结果报告在表11中。虽然最大和平均池化都是有效的,但平均池化实现了稍好的性能,证明其选择作为 squeeze 操作的基础是合理的。 但是,作者注意到SE块的性能对于特定聚合运算符的选择是相当强大的。

Excitation Operator
接下来作者评估excitation机制的非线性选择。 作者考虑另外两个选项:ReLU和tanh,并尝试用这些替代的非线性替换sigmoid。 结果报告在表12中。作者看到将 sigmoid 换成 tanh会 略微恶化性能,而使用 ReLU 则显著恶化,实际上导致SE-ResNet-50的性能降至低于ResNet-50基线的性能。 这表明,为了使SE块有效,仔细构造excitation算子是很重要的。

Different stages
作者通过将SE块整合到ResNet-50中来探索SE块在不同阶段的影响,一次一个阶段。 具体来说,作者将SE块添加到中间阶段:阶段2,阶段3和阶段4,并在表13中报告结果。作者观察到SE块在架构的每个阶段引入时都会带来性能优势。 此外,SE块在不同阶段引起的增益是互补的,因为它们可以有效地组合以进一步增强网络性能。

Integration strategy
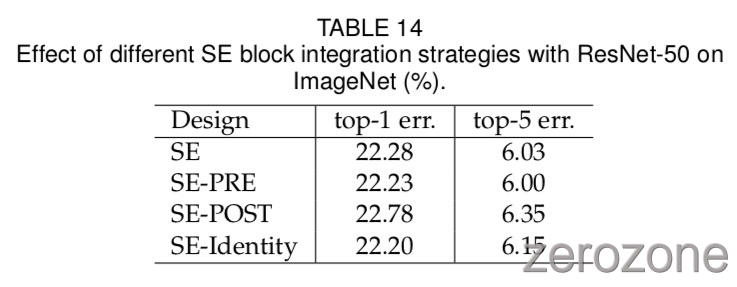
最后,作者进行消融研究,以评估SE块在将其集成到现有架构中时的位置的影响。 除了提出的SE设计之外,作者还考虑三种变体:(1)SE-PRE块,其中SE块在残差单元之前移动; (2)SE-POST块,其中SE单元在与identity分支的总和之后移动,以及(3)SE-Identity块,其中SE单元与残差单元并行地放置在 identity 连接上。 这些变体在图5中示出,并且每个变体的性能在表14中报告。作者观察到SE-PRE,SE-Identity和提议的SE块各自表现良好,而SE-POST块的使用导致性能下降。 该实验表明,SE单元产生的性能改进对于它们的位置是相当稳健的,只要它们在分支聚合之前应用。
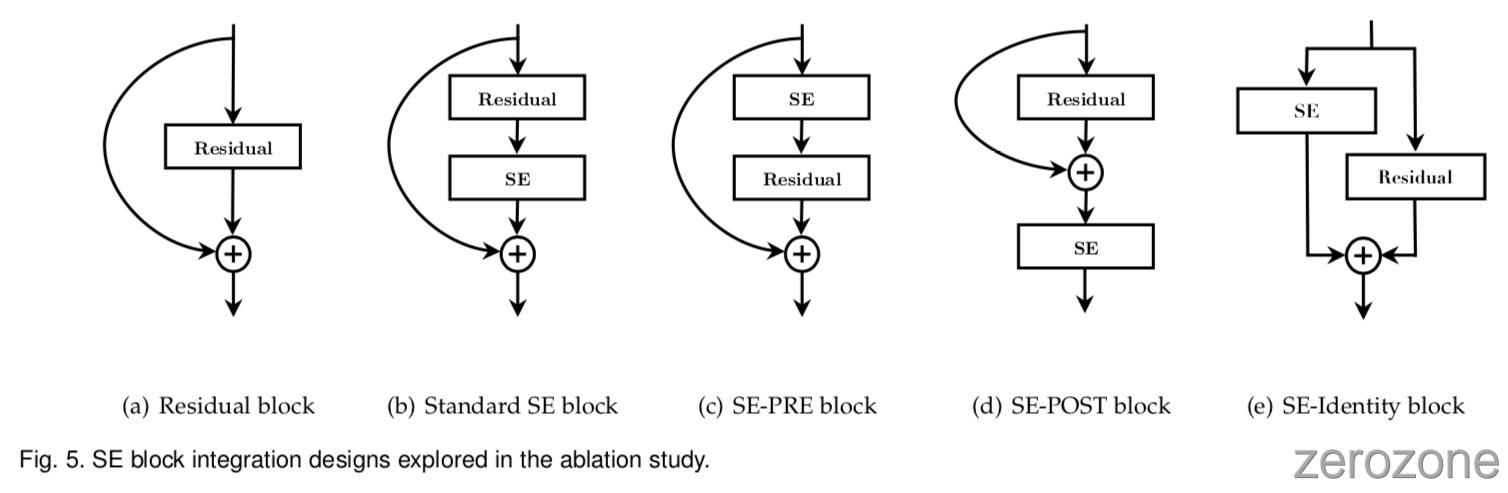
在上面的实验中,每个SE块被放置在残差单元的结构之外。 作者还构造了一种设计的变体,它将SE块移动到剩余单元内,直接放置在3×3卷积层之后。 由于3×3卷积层具有较少的信道,因此相应的SE块引入的参数的数量也减少了。 表15中的比较表明,SE 3×3变量具有比标准SE块更少的参数可比较的分类精度。 虽然这超出了这项工作的范围,但作者预计通过为特定架构定制SE块使用可以实现进一步的效率提升。

Role of SE Blocks
虽然已经证明所提出的SE模块可以改善多个视觉任务的网络性能,但作者还想了解 squeeze 操作的作用以及 excitation 机制在实践中如何运作。 不幸的是,对深度神经网络学习的表示进行严格的理论分析仍然具有挑战性。 因此,作者采用经验方法来检验SE区块所起的作用,目标是至少对其实际功能有一个原始的理解。
Effect of Squeeze
为了评估squeeze操作产生的全局嵌入是否在性能中起重要作用,作者尝试使用SE块的变体来添加相同数量的参数,但不执行全局平均池。具体来说,作者移除汇集操作并用excitation算子中相同的1×1卷积替换两个FC层,其中相同的通道尺寸,即NoSqueeze,其中excitation输出保持空间尺寸作为输入。与SE块相反,这些逐点卷积只能根据本地运算符的输出重新映射通道。在实践中,深层网络的后期层通常具有(理论上的)全局感知域,在NoSqueeze变体中不再能够在整个网络中直接访问全局嵌入。两种模型的准确性和计算复杂性与表16中的标准ResNet-50模型进行了比较。作者观察到全局信息的使用对模型性能有显着影响,强调了squeeze操作的重要性。此外,与NoSqueeze设计相比,SE块允许以计算简约的方式使用该全局信息。

Role of Excitation
为了更清楚地了解SE块中excitation算子的功能,本节作者将研究SE-ResNet-50模型的示例激活,并检查它们在网络中不同深度的不同类别和不同输入图像的分布情况。特别是作者想要了解不同类别的图像和类中的图像之间的excitation是如何变化的。
作者首先考虑不同类别的excitation分布。 具体来说,作者从ImageNet数据集中抽取四个具有语义和外观多样性的类,即金鱼,哈巴狗,飞机和悬崖(这些类的示例图像如图6所示)。 然后,作者从验证集中为每个类抽取50个样本,并计算每个阶段的最后一个SE块中的50个均匀采样通道的平均激活(紧接在下采样之前)并绘制它们在图7中的分布。作为参考,作者还 绘制所有1000个类别中平均激活的分布。


作者对excitation操作的作用进行了以下三个观察。 首先,不同类别的分布在网络的早期层非常相似,例如, SE 2 3.这表明特征频道的重要性很可能在早期阶段由不同的阶层共享。 第二个观察是,在更深的地方,每个通道的值变得更具有特定类别,因为不同的类对特征的辨别值表现出不同的偏好,例如, SE 4 6和SE 5 1.这些观察结果与之前的工作[81],[82]中的发现一致,即早期的图层特征通常更为通用(例如,在分类任务的上下文中类别不可知),而后期图层特征 表现出更高水平的特异性[83]。
接下来,作者在网络的最后阶段观察到一些不同的现象。 SE 5 2表现出一种有趣的趋势,即饱和状态,其中大多数激活接近于1,其余的接近于零。 在所有激活取值1的点处,SE块减少到身份运算符。 在SE 5 3中的网络结束时(紧接着是分类器之前的全局汇集),类似的模式出现在不同的类别上,直到规模的微小变化(可以通过分类器调整)。 这表明 SE_5_2 和 SE_5_3 在提供网络重新校准方面不如以前的块重要。 这一发现与第二节中的实证研究结果一致。 图4证明了通过去除最后阶段的SE块而仅略微损失性能可以显着减少附加参数计数。
最后,作者展示了图8中两个样本类(goldfish 和 plane)在同一类中的图像实例的激活的平均值和标准偏差。作者观察到与类间可视化一致的趋势,表明动态行为 SE块的类别和类中的实例都有所不同。 特别是在网络的后续层中,在单个类中存在相当多的表示,网络学习利用特征重新校准来改善其辨别性能。 总之,SE块产生特定于实例的响应,然而这些响应用于支持架构中不同层的模型越来越特定于类的需求。

Conclusion
在本文中,作者提出了SE模块,这是一种架构单元,旨在通过使网络执行动态通道特征重新校准来提高网络的表示能力。 大量实验证明了SENets的有效性,它在多个数据集和任务中实现了最先进的性能。 此外,SE模块揭示了先前架构无法充分模拟通道方面的特征依赖性。 作者希望这种见解可能对其他需要强烈判别功能的任务有用。 最后,SE块产生的特征重要性值可以用于其他任务,例如用于模型压缩的网络修剪。
Appendix: Details of SENet-154
SENet-154是通过将SE块整合到64×4d ResNeXt-152的修改版本中构建的,该版本通过采用ResNet-152 [13]的块堆叠策略扩展了原始的ResNeXt-101 [19]。该模型的设计和训练的进一步差异(超出SE块的使用)如下
- 每个瓶颈构件的第一个1×1卷积通道的数量减半,以降低模型的计算成本性能降低最小化。
- 将第一个7×7卷积层替换为三个连续的3×3卷积层。
- 用步长-2卷积的1×1下采样投影用3×3步幅-2卷积代替以保存信息。
- 在分级层之前插入脱落层(具有0.2的压差比)以减少过度拟合。
- 在训练期间使用标签平滑正则化(如[20]中所述)。
- 所有BN层的参数在最后几个训练时期被冻结,以确保训练和测试之间的一致性。
- 使用8台服务器(64个GPU)并行执行培训,以实现大批量(2048)。初始学习率设定为1.0。