文章: MobileNetV2: Inverted Residuals and Linear Bottlenecks
作者: Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
备注: Google
摘要
本文中作者介绍了一个新的网络结构, MobileNetV2, 提高了移动模型在多个任务和基准以及不同模型大小的最好性能. 作者还介绍了将这些 Mobile 模型应用的目标检测上的有效方法, 并给出了一个新的框架, SSDLite. 此外, 作者还演示了如何通过一个简化形式的 DeepLabv3 (作者称之为 Mobile DeepLabv3)来构建移动语义分割模型.
作者的模型基于逆置残差结构(Inverted Residual Structure), 该结构中的 shortcut 连接位于 bottleneck 的网络层之间. 中间的 expansion layer 使用了轻量级的 Depthwise Conv 来过滤特征, 将结果传给非线性激活层. 此外, 作者发现在 narrow layers 中去除非线性层对于保持表征能力来说是非常重要的. 作者证明了这样做可以提供性能, 同时给出了这种设计的 Intuition.
最后, 作者的方法还可以让输入输出和 expressiveness of the transformation 解耦, 这为进一步的分析提供了一个方便的框架. 作者在 ImageNet 分类数据集, COCO 目标检测数据集, VOC 实例分割数据集上测试了模型的性能. 同时还评估了精度, 乘法加法操作次数, 实际延迟和参数数量之间的 trade-offs.
Introduction
本文的主要贡献是一个新型的 layer module: the inverted residual with linear bottleneck. 该模块采用低维压缩表征作为输入, 首先将其扩展至高维, 然后用轻量级的 Depthwise Conv 进行滤波. 特征随后会被一个 linear convolution 投影回低维表征.
这些模块可以利用现有的任何框架中的标准操作实现, 并且可以取得 sota 的效果. 此外, 本文提出的卷积模块特征适合用移动设计, 因为它允许通过 “never fully materializing large intermediate tensors” 来显著减少 Inference 过程中所需的内存占用. 这减少了许多嵌入式硬件设计对主存访问的需求, 这些设计提供了非常快的软件控制的高速缓存.
Related Work
Network Pruning
Connectivity Learning
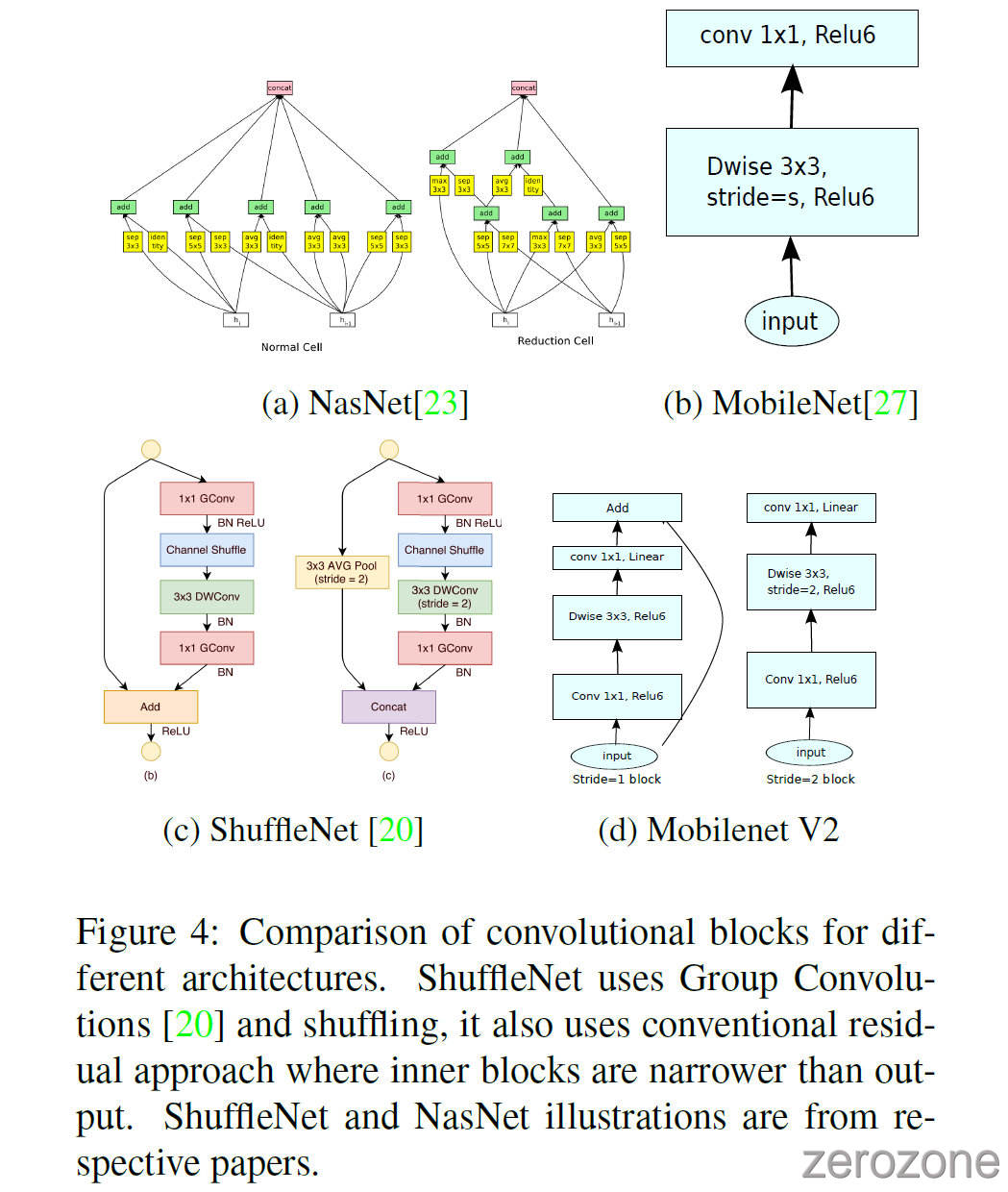
ShuffleNet
Architectural Search: genetic algorithms, reinforcement learning
Preliminaries, discussion and intuition
Depthwise Separable Convolutions
Depthwise Separable Convolutions 在 MobileNet 和 Xception 中是非常关键的一个模块, 这里作者也同样在网络中使用. 其基本思想就是将原始的标准卷积操作分解良两个独立的卷积层. 第一个卷积层称为 Depthwise Conv, 它对 每个输入通道分别应用一个独立的卷积滤波器来进行轻量级的滤波. 第二个卷积层称为 Pointwise Conv(1x1 Conv), 它负责通过计算输入通道的线性组合来建立新的特征图谱.
当标准卷积层的输入图谱为 $h_i\times w_i\times d_i$, 卷积核为 $R^{k\times k\times d_i\times d_j}$, 输出图谱为 $h_i\times w_i\times d_j$ 时, 则该卷积的计算成本为: $h_i \cdot w_i \cdot d_i \cdot d_j\cdot k\cdot k$.
Depthwise Separable Conv 是对标准卷积层的一种替代. 从经验上看, 它们的效果几乎和标准卷积一样好, 只不过成本更低, 如下所示(Depthwise 和 Pointwise 的计算成本之和):
可以看出, 与标准卷积层相比, 深度可分离卷积有效的减少了几乎 $k^2$ 被的计算量. 在 MobileNetV2 中, 作者队 $k=3$ 的卷积层使用深度可分离卷积, 因此计算成本可以降低 8~9 倍, 同时精度只降低一点.
Linear Bottlenecks
对于具有 $n$ 层网络层的深度神经网络来说, 每一个网络层 $L_i$ 都具有 $h_i\times w_i\times d_i$ 维度的 activation tensor. 在本节中, 作者将讨论这些 activation tensors 的基本性质, 并将这些 tensors 看做是具有 $d_i$ 维度的 $h_i\times w_i$ 大小的像素容器. 非正式的说, 对于实际图像的输入集, 作者称网络层的 activations (对于任意的网络层 $L_i$) 集合组成了一个 “manifold of interest”. 长期以来, 人们一直认为神经网络中的 manifolds of interest 可以嵌入到低维的子空间中. 换句话说, 当作者深层的卷积层中所有单独的 $d$ 通道的 像素 时, 这些值中编码的信息实际上存在于一些 manifold 中, 而这些 manifold 又可以嵌入到低维的子空间中. (注意, manifold 的维度不同于通过线性变换嵌入的子空间维度)
粗略来看, such a fact 可以通过简单的减少一个层的维度来捕获和利用, 从而减少操作空间的维度. MobileNetV1 成功的利用了这一点, 通过 width multiplier 超参数可以有效的在计算成本和精度之间进行权衡, 并且该方法已经被纳入其他网络的有效模型设计中. 根据这种 Intuition, width multiplier 方法允许降低 activation space 的维度, 直到 manifold of interest 覆盖整个空间. 但是, 当作者回忆起深度卷积神经网络的在每个坐标点上的转换都是非线性的使用, 例如 ReLU, 这种 Intuition 就不成立了. 例如, ReLU 在一维空间中时, 会产生一条射线, 但是在 $R^n$ 维空间中时, 通常会产生一条具有 $n$ 个连接的分段线性曲线.
It is easy to see that in general if a result of a layer transformation ReLU($Bx$) has a non-zero volume $S$, the points mapped to interior $S$ are obtained via a linear transformation $B$ of the input, thus indicating that the part of the input space corresponding to the full dimensional output, is limited to a linear transformation. 换句话说, 深度网络只有在输出域(output domain)的非零部分(non-zero volume part)才具有线性分类器的能力.
另一方面, 当 ReLU collapses the channel 时, 它不可避免的会丢失该通道中的信息. 然而, 如果作者有很多个通道, 并且在 activation manifold 中有一个结构, 那么信息可能仍然保存在其他通道中. 在补充材料中, 作者证明了如果 input manifold 可以嵌入到激活空间的一个显著的低维子空间中, 那么在将所需的复杂度引入到表征函数集合中时, ReLU 变换可以保留一定的信息.
综上所示, 作者强调了两个特性, 它们表明了 manifold of the interest 在高维 activation space 中嵌入到低维子空间的要求:
- 如果 manifold of interest 在 ReLU 变换后保持非零体积, 则对应线性变换.
- ReLU 能够保存 input manifold 的完整信息, 但前提是 input manifold 位于属于空间的低维子空间当中.


这两个性质为作者优化现有的神经结构提供了经验性的提示: 假设 manifold of interest 是低维的, 那么作者可以通过在卷积块中插入 linear bottleneck 来捕获它. 实验证据表明, 使用线性层是至关重要的, 因为它可以防止非线性层破坏太多的信息. 在第 6 节, 作者会展示在 bottlenecks 中使用非线性层实际上会损害最终的精度, 进一步验证了作者的假设.
在本文的其余部分, 作者将使用 bottleneck , 并且作者将 bottleneck 的输入大小和内部大小的比值称为膨胀比(expansion ratio).
Inverted residuals
Bottleneck Blocks 和 Residual Blocks 类似, 其中每个块包含一个输入, 然后是若干 bottlenecks, 然后是 expansion. 有一种 Intuition 认为 Bottleneck 包含了所有的必要信息, 而 expansion layer 仅仅作为伴随张量非线性变换的实现细节, 受到该观点的启发, 作者直接在 Bottlenecks 之间使用 shortcut. 图3提供了不同设计的示意图. 插入 shortcut 的动机和传统的残差连接类似: 作者想要提高梯度跨多层传播的能力. 在第5节中显示了 Inverted 的设计大大提高了内存效率, 并且在本文的实验中效果更好一些.

Running time and parameter count for bottleneck convolution 基本的实现结构如表1所示. 在表3中, 作者比较了 MobileNetV1, MobileNetV2, ShuffleNet 所需的分辨率大小.




Information flow interpretation
作者的网络结构的一个有趣的特性是, 它在 building blocks(bottleneck layers) 的 input/output domains 和层转换之间提供了一种自然的间隔(natural separation). 层转换是一个将输入转换为输出的非线性函数, 前者可以看做是网络在每一层的容量(capacity), 而后者可以看做是表征能力(expressiveness). 这与传统的卷积块形成了鲜明的对比, 传统的卷积是 regular and separable 的, 它的 expressiveness 和 capacity 是纠缠在一起的, 是输出图谱通道数的函数. 特别地, 在作者的例子中, 当内层网络的深度为 0 时, 多亏了 shortcut 的存在, 使得底层卷积变成了一个 indentity function. 当膨胀比(expansion ratio)小于 1 时, 这就是一个经典的残差卷积块. 但是, for our purposes, 作者展示了大于 1 的膨胀比是最有用的.
这一解释使得作者能够不考虑 capacity 而独立的研究网络的表征能力, 作者认为, 对这种 separation 的进一步探索有助于更好的理解网络的特性.
Model Architecture
接下来作者将详细描述作者的网络结构. 正如前一节所讨论的, 基本的 building block 是 bottleneck depth-separable convolution with residuals. 该模块的详细结构如表 1 所示. MobileNetV2 的网络结构如表2 所示, 第一层是一个 filters 数量为 32 的卷积层, 后面 19 个 residual bottleneck 层. 由于 ReLU6 在面对低精度计算时具有更高的鲁棒性, 因此作者选它作为非线性激活函数. 作者的卷积核大小通常为 3x3, 并在训练中使用 dropout 和 BN.


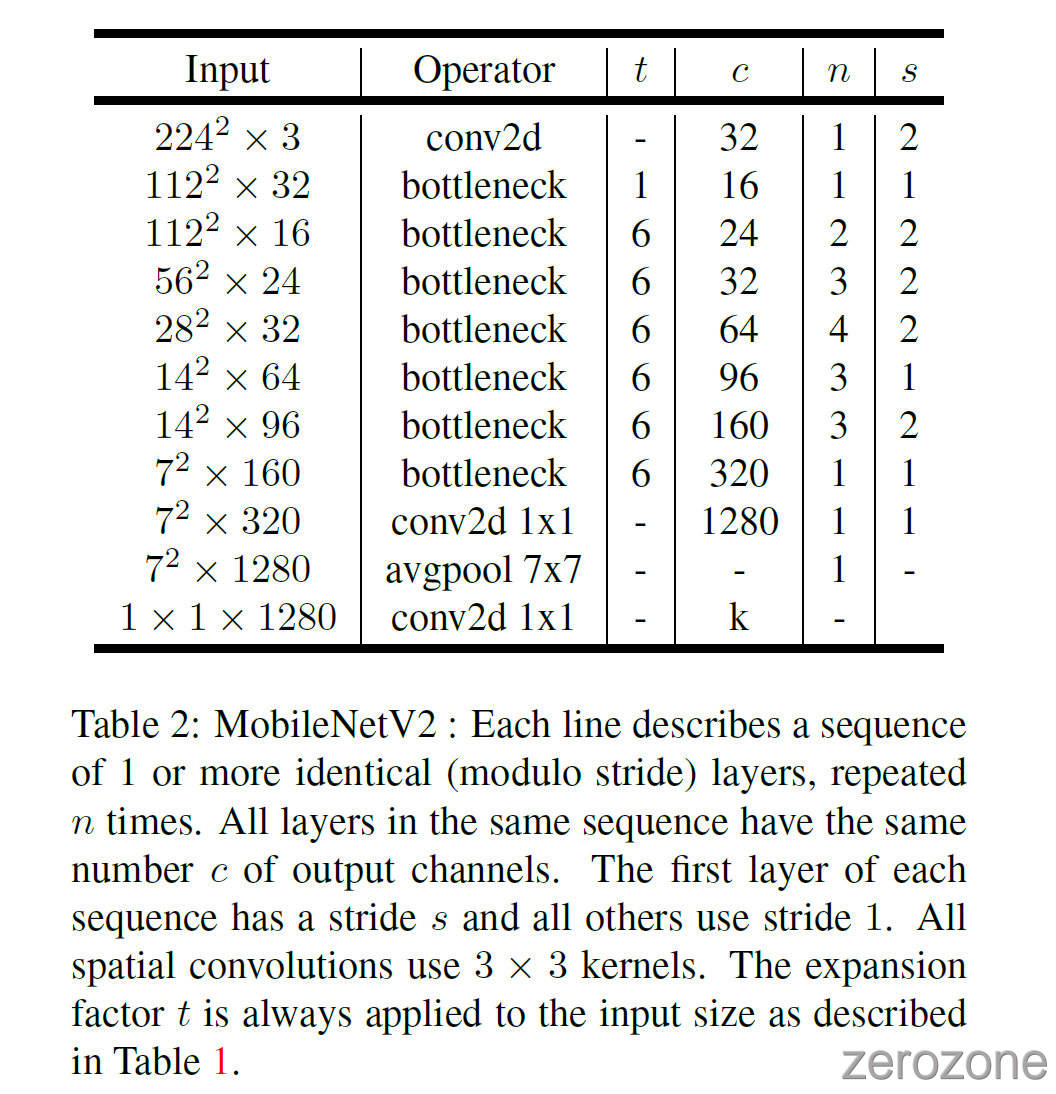
除了第一层以外, 作者在整个网络中都使用了恒定的膨胀率. 在作者的实验中, 作者发现在膨胀率在 5~10 之间时具有几乎相同的性能曲线, 并且在较小的网络中小膨胀率性能更好, 在较大的网络中大膨胀率性能较好.
在作者主要的实验中, 均使用大小为 6 的膨胀因子. 例如, 对于一个输入通道数为 64, 输出通道数为 128 的 bottleneck 模块来说, 中间的 expansion layer 的通道数为 $64\times 6 = 384$.
Trade-off hyper parameters 和 MobileNetV1 中一样, 作者将输入图像的分辨率和宽度乘子作为可调节的超参数, 根据所需的精度和性能要求权衡作者的体系结构, 以此适应不同的性能. 作者的 primary network(width multiplier 1, 224x224) 的计算成本为 3 亿次 multiply-adds, 并且具有 3.4 million 的参数. 作者探索了从 resolution 才 96 到 224, width multipliers 从 0.35 到 1.4 的性能表现. 网络的计算成本在 7~585 M MAdds, 模型大小在 1.7~6.9M 个参数.
MobileNetV2 在实现上与 MobileNetV1 的一个小的差异是, 对于小于 1 的乘数, 作者将 width multiplier 应用于除最后一个卷积层之外的所有层. 这对小模型的性能有所提升.
Implementation Notes
Memory efficient inference
Inverted Residual Bottleneck 可以实现时具有内存高效的好处, 这对于移动应用来说非常重要. 计算过程会优先使需要在内存中的张量总数最小化来进行安排. 在通常情况下, 深度学习框架(TF, Caffe)会搜索所有可能的计算顺序 $\Sigma (G)$, 并从中选择总计算量最小的一个.
上式中, $R(i, \pi, G)$ 是连接到任意 $\pi_i, …, \pi_n$ 节点的中间张量列表, $|A|$ 代表了张量 $A$ 的大小, $size(i)$ 代表在操作 $i$ 起见内部存储所需要的内存总量.
对于只有平凡并行结构的图(如残差连接), 只有一个 non-trivial 的计算顺序, 因此可以简化计算图 $G$ 推理所需的总量和内存边界.
重申一下, 内存量就是所有操作中输入和输出的最大总大小. 在下面, 作者表明, 如果作者把一个 bottleneck residual block 作为一个单独的操作(将 inner convolution 作为一次性张量), 总的内存量大小将会由 bottleneck tensors 的大小决定, 而不是由 bottleneck 内部的 tensor 大小决定(much larger).
Bottleneck Residual Block 图3(b) 中的操作可以看做三个子操作: Linear transformation, Non-linear per-channel transformation, Linear transformation.
在作者的网络中, 作者非线性激活层为: ReLU6+dwise+ReLU6. Balablabla…(关于具体实现时的计算成本)
Experiments
ImageNet Classification
Training setup: TensorFlow, RMSPropOptimizer(decay = 0.9, momentum = 0.9), BN (after every layer), weight decay = 0.00004, initial lr = 0.045, lr decay = 0.98 per epoch, 16 GPU asynchronous(异步) workers, batch size = 96.
Results: 如表4, 图5所示.


Object Detection
SSDLite: 用深度可分离卷积替换标准卷积, 大幅降低 Params 和 MAdds, 如表5所示. 关于 mAP, 参数量, 乘法加法次数的测试和比较如表6所示.
Semantic Segmentation
DeepLabv3, 结果如表7所示.

Ablation study
Inverted residual connections: shortcut connecting bottleneck perform better than shortcuts connecting the expanded layers, 如图6(b)所示
Importance of linear bottlenecks 线性 bottleneck 模型严格来说没有非线性模型强大, 因为激活总是可以在线性状态下运行, 并对 bias 和 scale 进行适当的改变. 但是作者的实验结果如图6所示, 线性 bottleneck 提高了性能, 为非线性破坏低维空间中的信息提供了补救措施(providing support).
