什么是引用? 声明和使用引用时要注意哪些问题?
引用就是某个变量的”别名”(alias).
声明一个引用的时候, 切记要对其进行初始化.
声明完毕后, 相当于目标变量具有了两个名称, 即原名称和引用名, 引用名与该变量绑定, 不能再把该引用名作为其他变量名的别名.
对引用求地址, 就是对目标变量取地址, 即我们常说引用名是目标变量名的一个别名. 注意, 引用是不占据空间的, 虽然编译器一般将引用实现为const指针, 即指向位置不可变的指针. 但是一般编译器对引用会设置一些限制条件, 因此从程序员的角度来说, 我们认为引用就是别名, 也就是它不占据空间.
不能建立引用的数组. 因为数组是一个由若干个元素所组成的集合, 所以无法建立一个由引用组成的集合. 但是可以建立数组的引用(即数组的别名)
1 | int x=2,y=3,z=4; |
引用和指针的关系与区别?
关系:
编译器一般会将引用实现为const指针, 所以可以将引用看做是一种特殊的指针
区别:
- 指针也是一种变量, 引用则是变量的别名
- 指针可以先声明再赋值, 引用必须在定义的同时初始化
- 指针可以重新指向其他变量, 引用一旦绑定就无法更改(行为上更像是常量指针)
- 指针占用内存大小, 而引用不占内存大小(编译器会限制对引用的操作, 使得在程序员角度看来, 引用就是别名, 不占内存)
C++ PrimerPlus中对 对象 的定义是: 一块能存储数据并具有某种类型的内存空间. 也就是说, 一个对象, 它拥有 值 和 地址 两种属性, 在运行程序时, 计算机会为该对象分配存储空间, 来存储该对象的值, 我们可以通过该对象的地址, 来访问这一块存储空间中的值.
在 C++ 中, 指针 实际上也是一种 对象, 它同样拥有 值 和 地址 两种属性, 只不过指针存储的数据类型是其他对象的地址, 当我们想要通过来地址访问其他对象时, 就要使用”*“来访问.
而对象有常量和变量之分, 指针也一样, 在 C++ 中, 常量指针是指这个指针的值是不可改变的, 也就是它所存储的地址是不可以改变的, 而指向常量的指针是指不能通过该指针来改变这个指针所指向的对象.
引用在行为上就更像是常量指针, 我们可以把它理解成是变量的别名, 在定义一个引用的时候, 程序时把该引用和它的初始值绑定在一起, 也就是说, 我们在定义引用的同时, 就必须对其进行初始化, 并且, 引用一经声明, 就不可以再与其他的变量绑定.
将引用作为函数参数有哪些特点?
- 由于引用可以看做是const指针, 因此传递引用给函数和传递指针给函数的效果是一样的, 这时, 被调函数的形参就成为原来主调函数中的实参变量或对象的一个别名来使用, 所以在被调函数中对形参变量的操作就是对其相应的目标对象的操作.
- 使用引用传递参数时, 在内存中并不会产生实参的副本, 因此, 当参数传递的数据较大时, 用引用的空间利用率高
将引用作为函数返回值类型的优势和注意事项?
优势:
在内存中不会产生被返回值的副本 ( 注意: 正是因为这个原因, 所以返回一个局部变量的引用是不可取的. )
注意事项:
- 不能返回局部变量的引用: 因为在内存中不会产生被返回值的副本, 随着该局部变量生存期的结束, 引用指向的变量就失效了, 此时会产生runtime error错误.
- 不要返回函数内部
new分配的内存的引用: 虽然不存在局部变量的自动销毁问题, 但是对于这种情况, 又是会面临其他尴尬局面. 例如, 被函数返回的引用只是作为一个临时变量出现, 而没有被赋予一个实际的变量, 那么这个引用所指向的空间(由new分配)就无法释放 很容易造成内存泄漏. - 可以返回对象成员的引用, 但最好是const. 主要原因是当对象的属性与某种业务规则相关联的时候, 其赋值常常与某些其他属性或者对象的状态有关, 因此有必要将赋值操作封装在一个业务规则中. 如果其他对象可以获得该属性的非常量引用(或指针), 那么对该属性的单纯赋值会破坏业务规则的完整性.
- 引用和流操作符的重载, 因为这两个操作符常常希望被连续使用, 因此这两个操作符重载时的返回值应该是一个仍然支持操作符特性的流引用
http://wyude.lofter.com/post/1cb19406_68f16ad
在什么时候需要使用常引用?
如果既要利用引用提高程序的效率, 又要保护传递给函数的数据不在函数中被改变, 就应该使用常引用, 同时如果传入的实参是const类型的变量, 则形参必须也声明为const. 通常, 如果引用型参数在能够被定义为const的情况下, 优先定义为const.
什么是右值引用?
左值引用就是对一个左值进行引用的类型。右值引用(C++11新特性)就是对一个右值进行引用的类型,事实上,由于右值通常不具有名字,我们也只能通过引用的方式找到它的存在。
右值引用和左值引用都是属于引用类型。无论是声明一个左值引用还是右值引用,都必须立即进行初始化。而其原因可以理解为是引用类型本身自己并不拥有所绑定对象的内存,只是该对象的一个别名。左值引用是具名变量值的别名,而右值引用则是不具名(匿名)变量的别名。
左值引用通常也不能绑定到右值,但 常量左值引用 是个“万能”的引用类型。它可以接受非常量左值、常量左值、右值对其进行初始化。不过常量左值所引用的右值在它的“余生”中只能是只读的。相对地,非常量左值只能接受非常量左值对其进行初始化。
1 | int &a = 2; # 左值引用绑定到右值,编译失败 |
右值引用本质上也是一种引用,只是它必须且只能绑定在右值上。由于右值引用只能绑定在右值上,而右值要么是字面常量,要么是临时对象,所以:
- 右值引用的对象,是临时的,即将被销毁
- 右值引用的对象,不会在其他地方使用
这两个特性意味着:接受和使用右值引用的代码,可以自由的接管所引用对象的资源,而无需担心对其他代码逻辑造成数据破坏
右值值引用通常不能绑定到任何的左值,要想绑定一个左值到右值引用,通常需要std::move()将左值强制转换为右值,例如:
1 | int a=2; |
右值引用本身是左值
右值引用本身是左值,通过下面的代码,我们发现,可以通过右值引用的名字得到他的地址,因此,右值引用本身就是左值:1
2int&& r1 = 2;
std::cout<<&r1; //编译通过,输出r1的地址
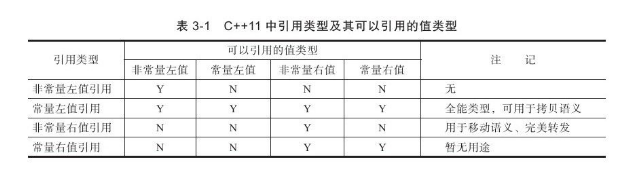
下表列出了在C++11中各种引用类型可以引用的值的类型。值得注意的是,只要能够绑定右值的引用类型,都能够延长右值的生命期。
左值、右值的概念:
C++11 对 C++98 中的右值进行了扩充。在C++11中右值又分为纯右值(prvalue,Pure Rvalue)和将亡值(xvalue,eXpiring Value)。
在C++11中可以取地址的的就是左值,反之,不能取地址的、没有名字的就是右值(将亡值或纯右值)。举个例子,int a = b+c, a 就是左值,其有变量名为a,通过&a可以获取该变量的地址;表达式b+c、函数int func()的返回值是右值,在其被赋值给某一变量前,我们不能通过变量名找到它,&(b+c)这样的操作则不会通过编译。
纯右值的概念等同于我们在C++98标准中右值的概念,指的是临时变量和不跟对象关联的字面量值;
左值与右值的根本区别在于是否允许取地址&运算符获得对应的内存地址
将亡值 是C++11新增的跟右值引用相关的表达式,这样表达式通常是将要被移动的对象(移为他用),比如返回右值引用T&&的函数返回值、std::move的返回值,或者转换为T&&的类型转换函数的返回值。右值引用本身就是一个xvalue。
不能根据在等号左边还是右边来判断左值和右值
左值出现在等号右边的情况:1
2int a = 2;
int c = a;
右值出现在等号左边的情况(不能作为赋值的对象,赋值没有意义):1
((i>0) ? i : j) = 1;
右值、将亡值
在理解C++11的右值前,先看看C++98中右值的概念:C++98中右值是纯右值,纯右值指的是临时变量值、不跟对象关联的字面量值。临时变量指的是非引用返回的函数返回值、表达式等,例如函数int func()的返回值,表达式a+b;不跟对象关联的字面量值,例如true,2,”C”等。
将亡值可以理解为通过“盗取”其他变量内存空间的方式获取到的值。在确保其他变量不再被使用、或即将被销毁时,通过“盗取”的方式可以避免内存空间的释放和分配,能够延长变量值的生命期。